BNP Paribas Cardif Challenge
First Place Solution - Deep Learning, Transformers
Objective:
Competition organized by BNP Paribas Cardif & Domino Datalab and consisted in predicting a food’s nutrient score based on its composition.

Participants:
Around 100 students from Chile, Colombia, Peru and Mexico competed in the Data Science Challenge that was developed in Latin America.
Data Available:
The amount of carbohydrates, protein, vitamins , provenance, type of packaging, place of production, ingredients as text, etc. Download data here
Solution
All experiements we developed in Kfold validation. See folder 02.Code/
- First we fine-tuned a Roberta Transformer only with concatenated text features.
- After this we trained a lightgbm combining embeddings extracted from the transformer and numerical features.
- Finally we ensemble kfold predictions for final submission.
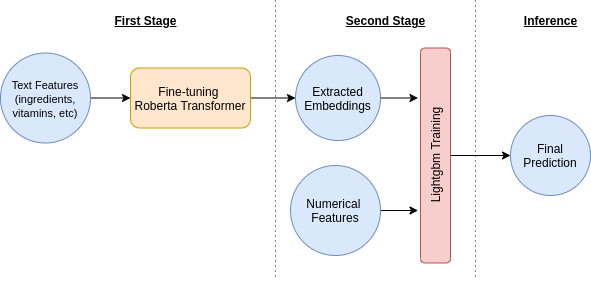
Fig. Training stages: 1. Roberta Finetuning, 2. Kfold - Lightgbm training
Code
See the solution and code in the github repository